切换导航
首页
服务项目
知识付费
COZE扣子实操教学
京东外卖基础运营
美团私人影院基础运营
美团闪购基础运营
美团医美高级运营
口腔电商运营
生美电商运营
医美电商运营
联络我
会员中心
登录
注册
COZE能帮助你实现什么?
COZE扣子token费用
COZE扣子平台架构
手把手教COZE搭建案例
在COZE搭建一个 AI 翻译应用
通过模板搭建智能体
COZE 智能体
搭建COZE扣子 助手智能体
智能体基础设置 - 多 Agent 模式
智能体基础设置 - 对话流模式
智能体基础设置 - 设置模型
智能体基础设置 - 提示词
智能体添加 - 插件
智能体添加 - 工作流
智能体添加 - 触发器
智能体添加 - 卡片样式
智能体添加 - 知识
智能体添加 - 记忆
记忆 - 数据库
记忆 - 长期记忆
记忆 - 文件盒子
智能体 - 提升对话体验
对话体验 - 快捷指令
对话体验 - 声纹识别
对话体验 - 音视频通话
COZE 工作流
工作流 与 对话流
工作流使用限制
工作流常见问题
使用工作流
基础节点 - 开始和结束节点
基础节点 - 大模型节点
基础节点 - 插件节点
基础节点 - 工作流节点
业务逻辑节点 - 代码节点
业务逻辑节点 - 选择器节点
业务逻辑节点 - 意图识别节点
业务逻辑节点 - 循环节点
业务逻辑节点 - 批处理节点
业务逻辑节点 - 变量聚合节点
工作流 - 输入节点
工作流 - 输出节点
工作流数据库节点 - SQL 自定义节点
工作流数据库节点 - 新增数据节点
工作流数据库节点 - 查询数据节点
工作流数据库节点 - 更新数据节点
工作流数据库节点 - 删除数据节点
知识和数据节点 - 变量赋值节点
知识和数据节点 - 知识库写入节点
知识和数据节点 - 知识库检索节点
知识和数据节点 - 长期记忆节点
图像处理节点 - 图像生成节点
图像处理节点 - 画板节点
图像处理插件节点
音视频处理节点 - 视频生成节点
音视频处理节点 - 视频提取音频节点
音视频处理节点 - 视频抽帧节点
组件节点 - HTTP 请求节点
组件节点 - 文本处理节点
组件节点 - 问答节点
组件节点 - JSON 反序列化节点
组件节点 - JSON 序列化节点
触发器节点 - 设置定时触发器
删除定时触发器节点
查询定时触发器节点
会话管理节点 - 创建会话节点
修改会话节点
删除会话节点
查看会话列表节点
会话历史节点 - 查询会话历史节点
清空会话历史节点
消息节点 - 创建消息节点
修改消息节点
删除消息节点
查询消息列表节点
管理工作流版本
封装与解散工作流
插件
搜索结果
没有相关内容~~
智能体基础设置 - 设置模型
最新修改于
2025-08-03 14:03
扣子已接入多款大模型,支持对各种大模型进行精细化的参数设置,例如生成多样性、输入及输出设置等。各个模型支持调整的参数不同。 ## 选择模型 你可以在智能体的编排页面为智能体选择一个合适的大模型,例如对于长文生成或优化相关的智能体选择一个支持长文本的大模型、对于具有复杂业务逻辑的智能体选择一个支持 Function call 的大模型。选择模型并完成智能体的技能、知识等设置后,你也可以切换成不同的模型,测评各个模型在同一个智能体中的效果,选择最合适的模型。 各个订阅套餐支持的模型资源,请参考[模型服务](https://www.coze.cn/open/docs/guides/model_service)。 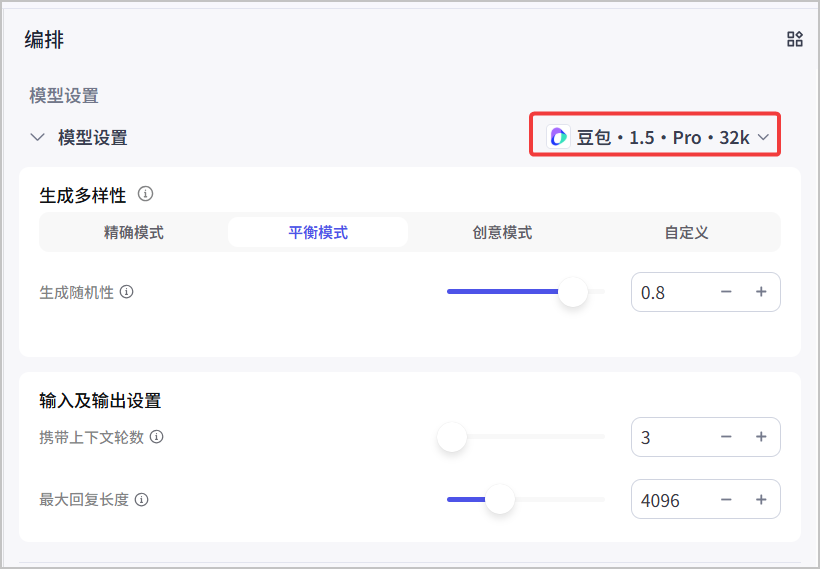 ## 生成多样性 用于从多个维度调整不同模型在生成内容时的随机性。扣子提供以下预置的模式供你选择,每个模式的模型参数取值不同。 * 精确模式:模型的输出内容严格遵循指令要求,可能会反复讨论某个主题,或频繁出现相同词汇。 * 平衡模式:平衡模型输出的随机性和准确性。 * 创意模式:模型输出内容更具多样性和创新性,某些场景下可能会偏离主旨。 你也可以根据需求,展开**高级设置**,修改每个模式下的具体参数值。建议不要同时调整生成随机性和 Top P,以免在多参数的影响下难以判断每个参数的调整效果。 | **配置项** | **说明** | | ------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | 生成随机性 | 即 temperature,用于控制结果的随机性。* 调高此参数值,会使模型的输出更具多样性和创新性。* 降低此参数值,会使输出内容更加严格遵循指令要求。当该数值接近零时,模型将变得确定和重复。在基于事实的问答场景,你可以使用较低的回复随机性数值,以获得更真实和简洁的答案,例如售后客服场景;在创造性的任务例如小说创作,你可以适当调高回复随机性数值。 | | Top P | 累计概率。模型在生成输出时会从概率最高的词汇开始选择,直到这些词汇的总概率累计达到 Top P 值。这样可以限制模型只选择这些高概率的词汇,从而控制输出内容的多样性。 | | 重复语句惩罚 | frequency penalty,用于控制模型输出重复语句的频率。当该值为正时,会阻止模型频繁使用相同的词汇和短语,从而增加输出内容的多样性。 | | 重复主题惩罚 | presence penalty,用于控制模型输出相同主题的频率。当该值为正时,会阻止模型频繁讨论相同的主题,从而增加输出内容的多样性。 | ## 输入及输出设置 用于指定模型的输出格式等参数,通常包括以下设置: | **配置项** | **说明** | | -------------- | ---------------------------------------------------------------------------------------------------------------------------------- | | 携带上下文轮数 | 设置代入模型上下文的对话历史轮数。轮数越多,多轮对话的相关性越高,但消耗的 Token 也越多。 | | 最大回复长度 | 智能体在生成提示和响应时,所输出的最大 token 数量,不同模型的 token 限制也不同。指定最大长度可以防止过长或不相关的响应并控制成本。 | | 输出格式 | 模型输出内容的格式,例如文本、Markdown。 | ## 上下文缓存 扣子的部分模型支持开启或关闭上下文缓存中的前缀缓存。开启前缀缓存后,可以将一些公共前缀内容进行缓存,后续调用模型时无需重复发送,从而加快模型的响应速度并降低使用成本。默认为关闭前缀缓存。前缀缓存适用于以下场景: * 标准化文本元素:需要生成大量文本输出的应用,例如自动邮件、通知或报告。 * 模板化内容:基于模板创建标准化内容,例如产品描述、招聘信息或个性化消息。 * 标准化的开头和结尾:生成开头和结尾遵循标准格式的文本内容,例如新闻摘要、报告或教育材料。 * 预先计算或预先格式化的信息:经常访问相同的预先计算的信息或预先格式化文本的应用,例如单位转换、数学公式或代码片段。 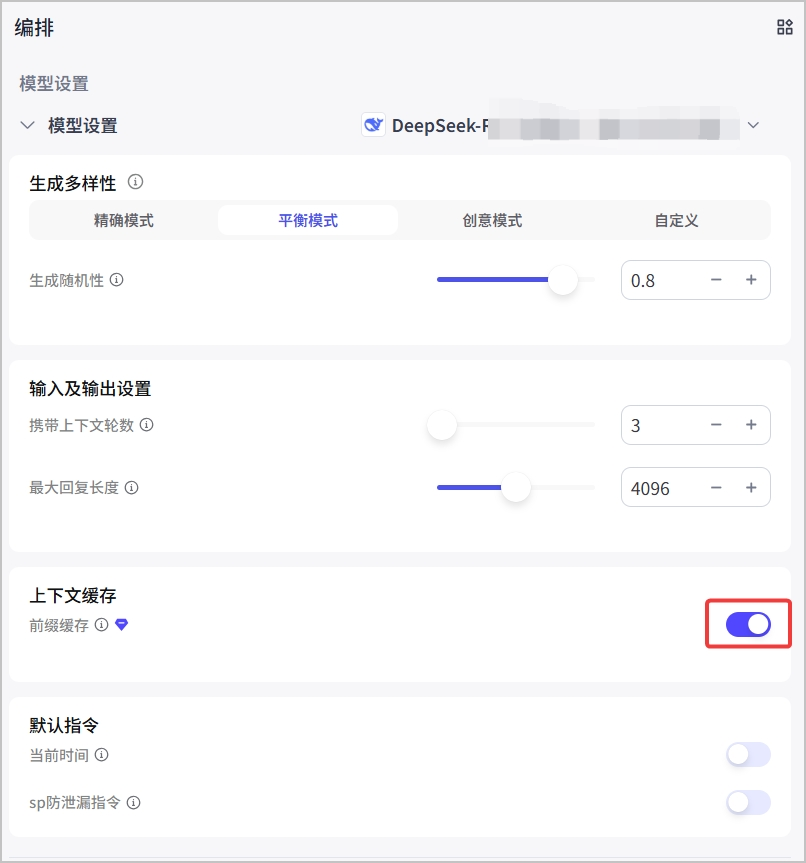 上下文缓存的使用限制如下: | **限制分类** | **说明** | | ------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | 套餐限制 | 仅扣子个人进阶版、团队版和企业版支持开启上下文前缀缓存。 | | 模型限制 | 仅如下模型支持前缀缓存:* doubao-1.5-pro-32k\_250115* doubao-1.5-lite-32k\_250115* doubao-pro-32k\_241215* deepseek-r1-distill-qwen-32b\_250120* deepseek-r1\_250120* deepseek-v3\_250324* deepseek-v3\_241226 | | 使用限制 | 开启前缀缓存后:* 模型不支持 Function Call,即工具调用。* 智能体不能使用插件、触发器、变量、数据库、文件盒子、不能添加工作流和对话流。* 不支持使用插件和工作流相关的快捷指令。* 智能体和应用不支持多人协作。* 提示词不能包含以下内容,否则无法命中缓存:* 获取当前时间* 变量* 插件* 提示词管理限制:不能提交到提示词库、不支持提示词对比调试、不支持自动优化提示词。 | * 开启前缀缓存后,发布到豆包时,前缀缓存不生效。 * 若需要在火山引擎方舟模型上使用上下文缓存,需要在[火山方舟控制台](https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement?LLM=%7B%7D&OpenTokenDrawer=false)开通上下文缓存功能。 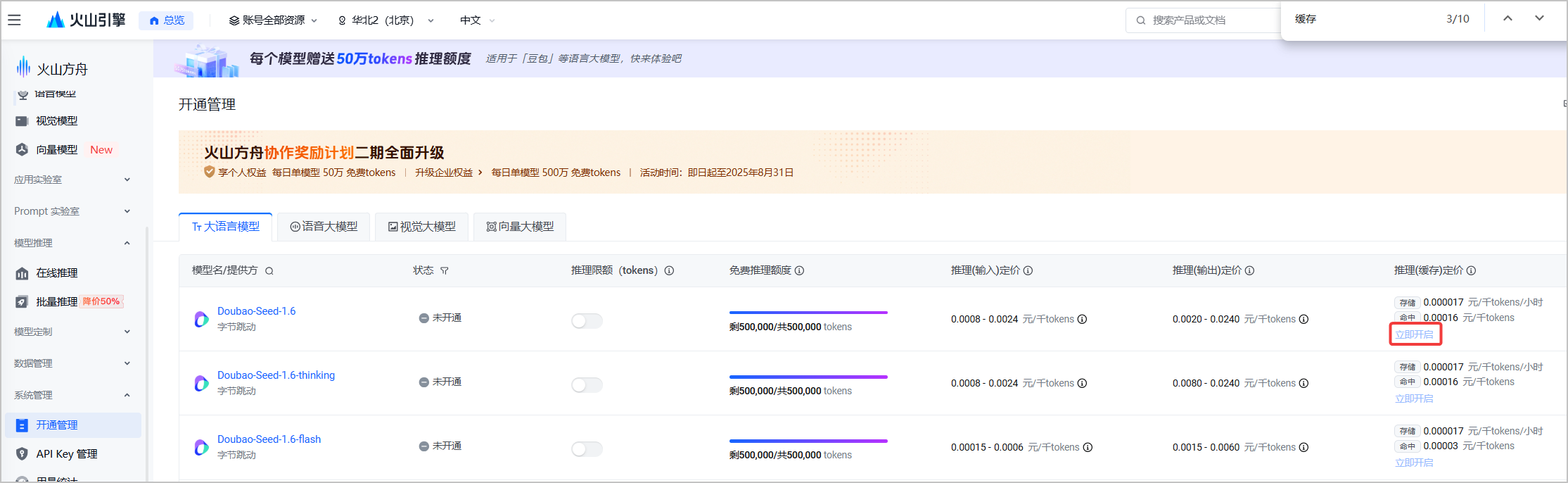 ## 默认指令 开启后,扣子将在对话中自动拼接并执行指令,包括: * 当前时间:开启后,智能体在与用户对话时能实时获取并提供准确的时间信息。 * 系统提示词防泄漏:开启后,当用户尝试获取或复述系统内部的规则、提示词或其他敏感内容时,智能体将礼貌地拒绝用户的请求,确保机密信息不被泄露。 ## 深度思考 部分支持深度思考的模型,开发者可以选择开启或关闭深度思考,从而灵活控制模型在交互过程中的 Token 消耗。默认为开启状态。 当前仅如下模型支持深度思考开关配置: * 豆包·1.6·自动深度思考·多模态模型 * 豆包·1.6·极致速度·多模态模型 * 豆包·1.5·Pro·视觉深度思考 * 豆包·GUI·Agent模型 * **开启深度思考**:开启后,智能体在与用户对话时会先输出一段思维链内容,通过逐步拆解问题、梳理逻辑,提升最终输出答案的准确性。但该模式会因额外的推理步骤消耗更多 Token。 开启深度思考后: * 模型不支持 Function Call,即工具调用。 * 智能体不能使用插件、触发器、变量、数据库、文件盒子、不能添加工作流和对话流。 * 不支持使用插件和工作流相关的快捷指令。 * **关闭深度思考**:关闭后,智能体将直接生成最终答案,不再经过额外的思维链推理过程,可有效降低 Token 消耗,提升响应速度。 * **自动**:当前仅**豆包·1.6·自动深度思考·多模态模型**支持该参数。启用自动模式后,模型会根据对话内容的复杂度,自动判断是否启用深度思考: * 简单问题(如事实查询、基础指令等):自动关闭深度思考,快速响应。 * 复杂问题(如逻辑推理、创意生成等):自动开启深度思考,保证答案质量。 ## 常见问题 ### 和模型对话时报错平台错误 * **场景**:和模型的智能体对话时,如果智能体回复“平台错误,请稍后再试或提交反馈”,且调试台中提示错误信息包含 empty result,表示模型没有回复,通常原因为本次对话较为复杂,触发了模型回复的 Token 限制。 * **解决方案**:对于处理逻辑复杂、对话消耗 Token 较多的模型,建议在模型设置中调大最大回复长度,也可以将智能体的模型更换为消耗 Token 较少、或处理 Token 的上限较大的模型。 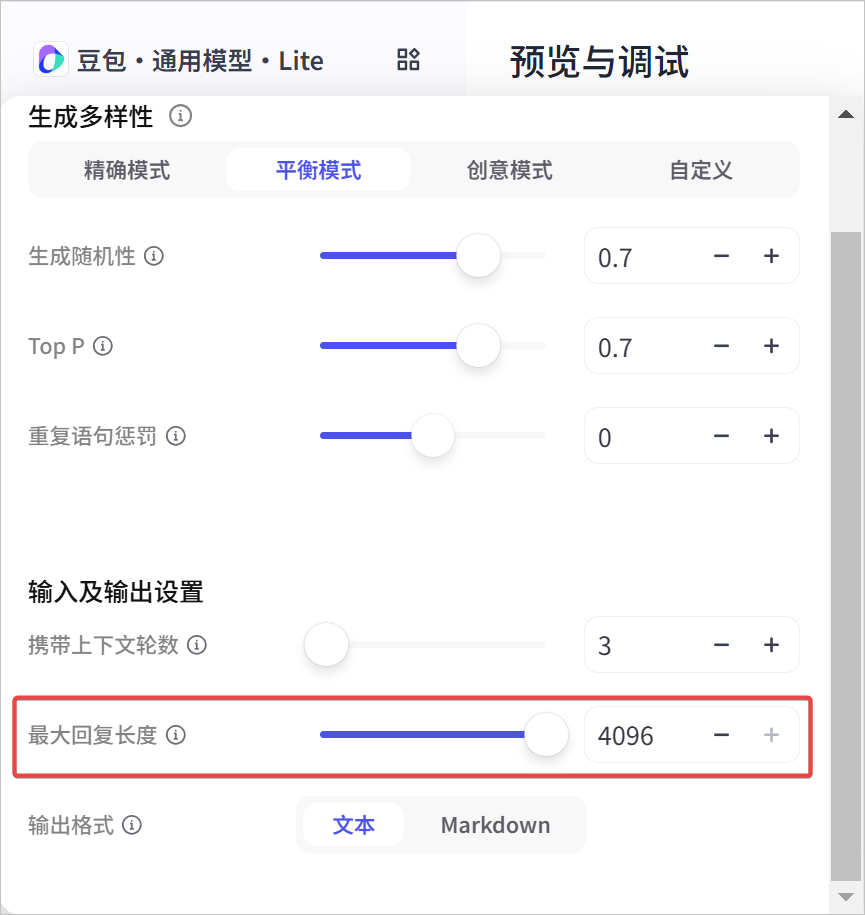 ### 问答智能体能否设置输入输出字数限制? 当前问答智能体暂不支持设置输入内容的 token 限制,但可通过大模型的**最大回复长度**参数控制模型输出的最大 token 量级以限制输出长度。 ### 智能体的响应时间是否比直接调用大模型更长? 扣子智能体的响应时间与调用的链路复杂度有关。如果智能体涉及到插件等工具的调用,可能比直接调用大模型耗时更久。
请输入访问密码
开始访问